SQL优化技巧 - PawSQL如何优化相关标量子查询?

在数据分析领域里,相关标量子查询(Correlated Scalar Subquery)无疑是一把双刃剑:它功能强大,能解决许多复杂问题,同时又因其复杂性给数据库优化器带来了不小的挑战。目前,只有像Oracle这样的商业数据库巨头在这方面做得相对出色。在国产数据库领域,也只有PolarDB对相关性子查询提供了一定的支持。本文不仅会介绍PawSQL如何对相关标量子查询进行基于代价的重写优化,还会展示PawSQL如何识别并合并查询中的多个类似标量子查询,从而进一步提升标量子查询优化的性能。通过PawSQL,您可以在MySQL/PostgreSQL等数据库上,体验Oracle般的重写优化能力。
🌟 相关标量子查询简介
在SQL的世界里,相关标量子查询(Correlated Scalar Subquery)是一种强大的工具,它允许子查询依赖于外部查询的列值。这与那些独立于外部查询的非相关标量子查询形成鲜明对比。相关标量子查询通过引用外部查询中的列,为每一行数据计算子查询的结果。
示例:
SELECT employee_name
FROM employees e
WHERE salary > (SELECT AVG(salary)
FROM employees
WHERE department_id = e.department_id);
在这个例子中,子查询计算每个部门的平均薪资,并与主查询中的salary进行比较,展示了相关标量子查询的强大功能。
🏎️ 挑战与机遇:数据库优化器的视角
相关标量子查询虽然强大,但也给数据库优化器带来了不小的挑战:
- 重复计算:在大数据集上,子查询可能会被重复计算,影响性能。
- 高计算开销:复杂的计算,如聚合函数,可能导致查询性能下降。
- 查询重写难题:将标量子查询转换为连接操作或其他形式并不总是容易的。
- 数据依赖性:优化效果依赖于数据分布和表结构,需要优化器灵活应对。
对于相关标量子查询,虽然解关联后的性能并不总是优于关联子查询,但基于代价的重写优化策略提供了新的视角。目前,只有少数数据库如Oracle和PolarDB实现了这些高级优化技术。
🚀PawSQL:相关标量子查询优化的新境界
PawSQL通过以下方式优化相关标量子查询:
- 基于代价的重写:支持条件和选择列中的标量子查询解关联。
- 合并重写:优化多个结构相似的标量子查询。
🎯 案例
原始查询:原查询使用了两个相关子查询(correlated subqueries),分别计算每个客户在特定日期的订单总价和订单数量。这种结构通常效率较低,因为需要为每个客户重复执行两个子查询。
SELECT c_custkey,
(SELECT SUM(o_totalprice)
FROM ORDERS
WHERE o_custkey = c_custkey AND o_orderdate = '2020-04-16') AS total,
(SELECT COUNT(*)
FROM ORDERS
WHERE o_custkey = c_custkey AND o_orderdate = '2020-04-16') AS cnt
FROM CUSTOMER
重写后的查询:PawSQL优化引擎将两个相关子查询合并为一个派生表(derived table),然后通过外连接(left outer join)与主查询关联。
SELECT c_custkey, SUM_ AS total, count_ AS cnt
FROM CUSTOMER LEFT OUTER JOIN (
SELECT o_custkey, SUM(o_totalprice) AS SUM_, COUNT(*) AS count_
FROM ORDERS
WHERE o_orderdate = '2020-04-16'
GROUP BY o_custkey) AS SQ ON o_custkey = c_custkey
性能提升:优化后,预计性能提升了1131.26%,这是一个显著的改进!
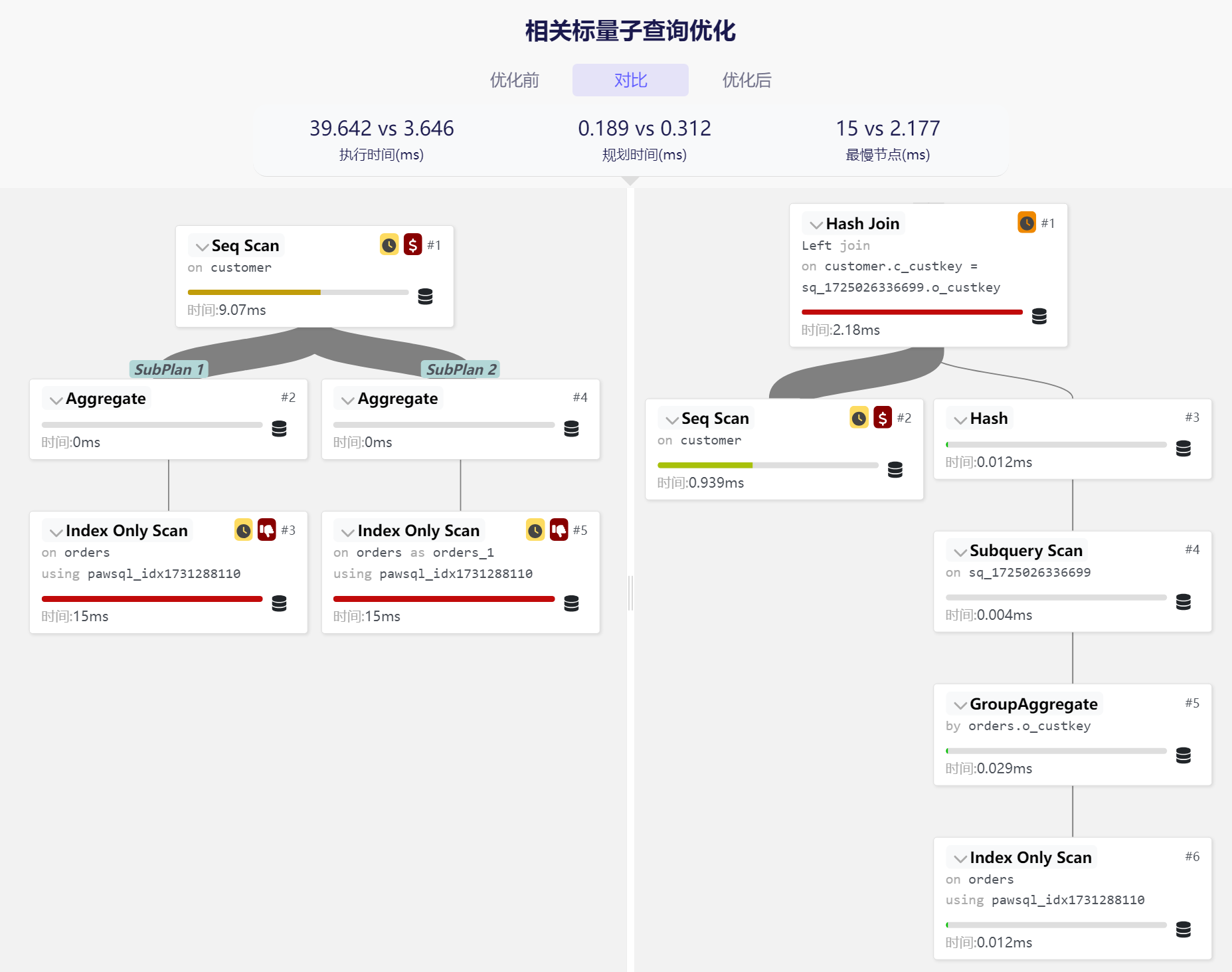
执行计划改进:
- 通过预先聚合 orders 表的数据,大大减少了需要处理的数据量
- 消除了重复的子查询执行,将两个子查询合并为一个
- 使用哈希连接来高效地关联 customer 和聚合后的 orders 数据
这个优化案例展示了PawSQL对于相关标量子查询重写技术的有效性。通过将多个相关子查询合并为一个派生表,并使用外连接,优化器能够显著减少重复计算和数据访问。
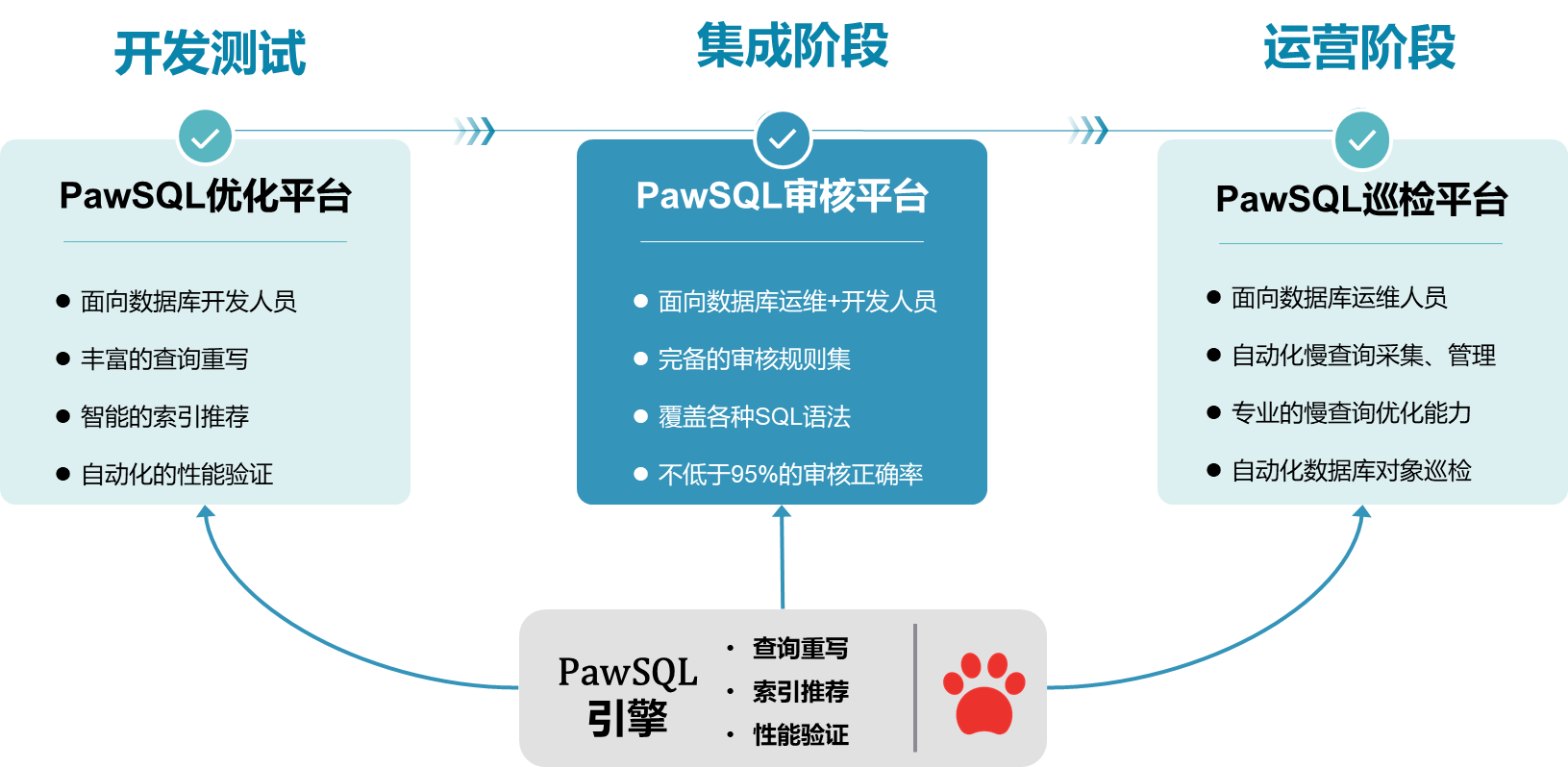
🌐关于PawSQL
PawSQL专注于数据库性能优化自动化和智能化,提供的解决方案覆盖SQL开发、测试、运维的整个流程,广泛支持MySQL、PostgreSQL、OpenGauss、Oracle等主流商用和开源数据库,以及openGauss,人大金仓、达梦等国产数据库,为开发者和企业提供一站式的创新SQL优化解决方案;有效解决了数据库SQL性能及质量问题,提升了数据库系统的稳定性、应用性能和基础设施利用率,为企业节省了大量的运维成本和时间投入。